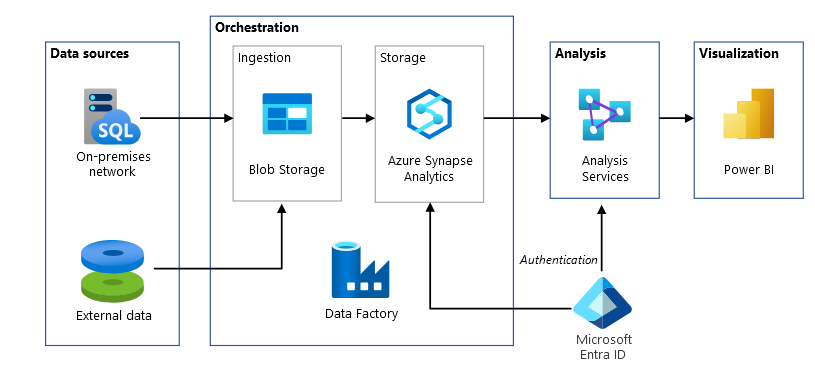
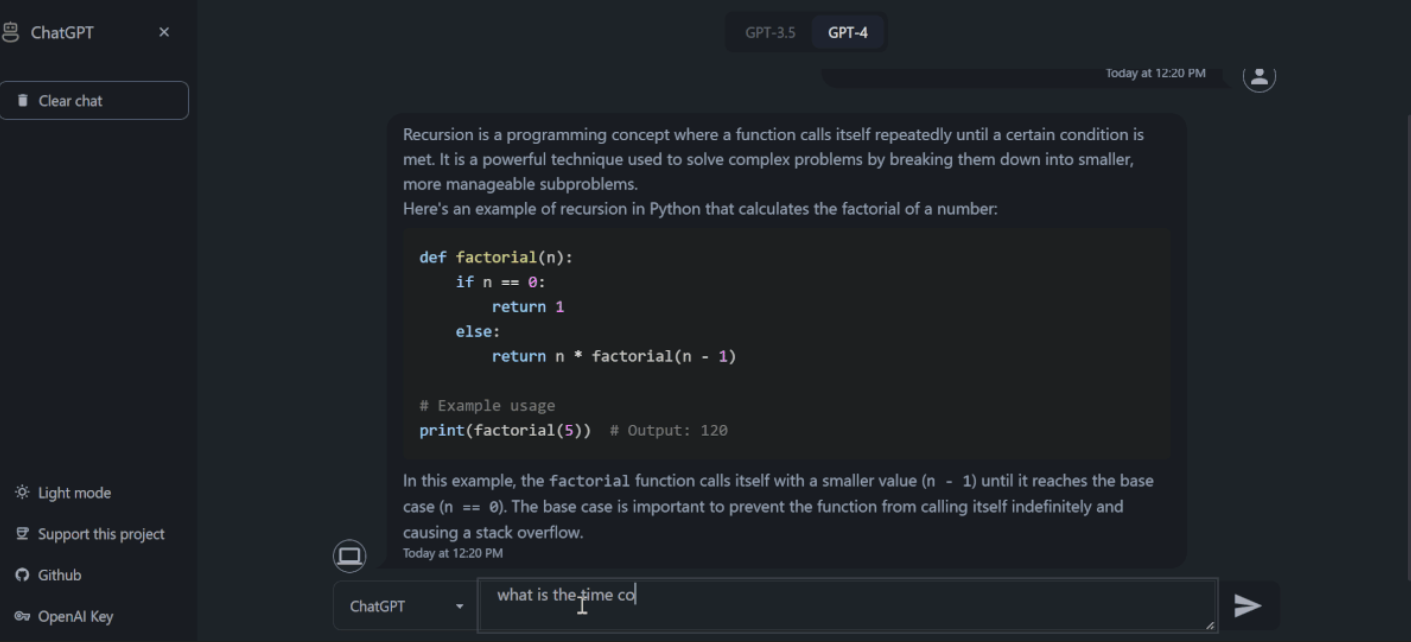
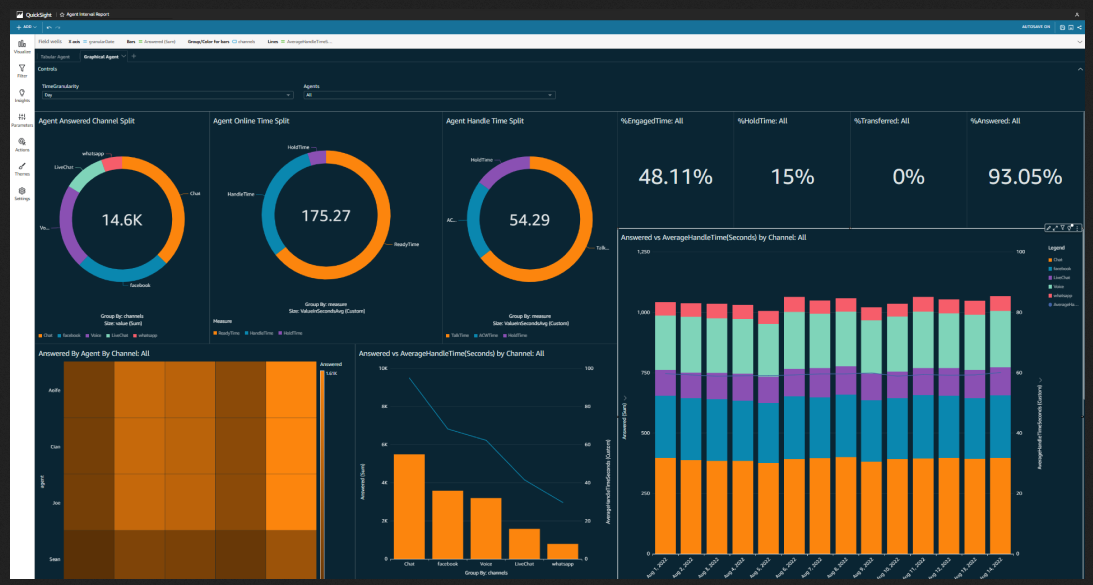
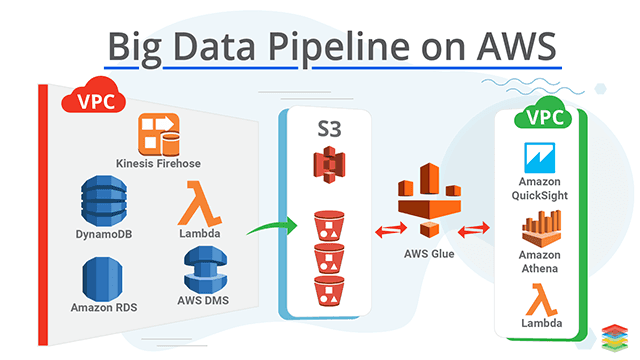
About me
Over 6+ years of experience in Data Engineering and Big Data Analytics, specializing in designing scalable data pipelines, enterprise data governance, and cloud-based analytics solutions. Expertise in Hadoop (Spark, Kafka, Hive), Azure (Data Factory, Databricks, Synapse), and AWS (Glue, Redshift, S3). Skilled in Python, SQL, SparkSQL, and Shell scripting for ETL automation and data transformation.
Proficient in Power BI, Tableau, Terraform, and Docker, with a strong focus on compliance frameworks like GDPR. Experienced in CI/CD pipelines, data modeling (Star, Snowflake schemas), and optimizing data warehouses for analytics. Collaborative team player delivering impactful, business-driven solutions.
What I'm Doing
-
Data Governance
Enterprise data governance, metadata management, and compliance frameworks (GDPR, HIPAA).
-
Data Tools
Expertise in Collibra, Informatica, Alation, and Apache Atlas.
-
Big Data Technologies
Skilled in Hadoop (HDFS, MapReduce), Apache Spark, and Hive.
-
Cloud Platforms
Proficient in AWS (Lambda, SageMaker, Redshift, Glue) and Azure (Data Factory, Synapse, AI Studio).
-
Documentation & Communication
Experienced in technical and business documentation, training delivery, and presentations.
-
Programming & Scripting
Expertise in Python, SQL, and Shell scripting.
-
Infrastructure & IaC
Proficient in Terraform, Docker, and Kubernetes.